부트캠프를 시작한지 벌써 한 달이 다되어간다.
이번 주에는 라이브 강의만 4번이 있었고 온라인 강의 또한 빽빽히 채워진 쉽지 않은 스케줄이었다.
Crawling으로 데이터 수집
데이터를 수집 및 다루기를 위한 크롤링을 진행하였다.
# jupyter notebook을 기준으로 작성됨
# selenium 설치
!pip install selenium
!pip install webdriver-manager
selenium을 통해 크롬 드라이버로 크롬 브라우저를 컨트롤 할 수 있으며, 이를 위한 설치를 진행하였다.
from selenium import webdriver
browser = webdriver.Chrome()위의 명령어를 통해 크롬브라우저를 따로 실행하였다.
browser.get('http://weather.naver.com')간단히 실행해보기 위해 네이버 날씨 데이터를 가져오기 위한 url을 입력하였다.

가져오려는 정보를 선택 후, 마우스 우클릭하여 검사를 선택하였다.
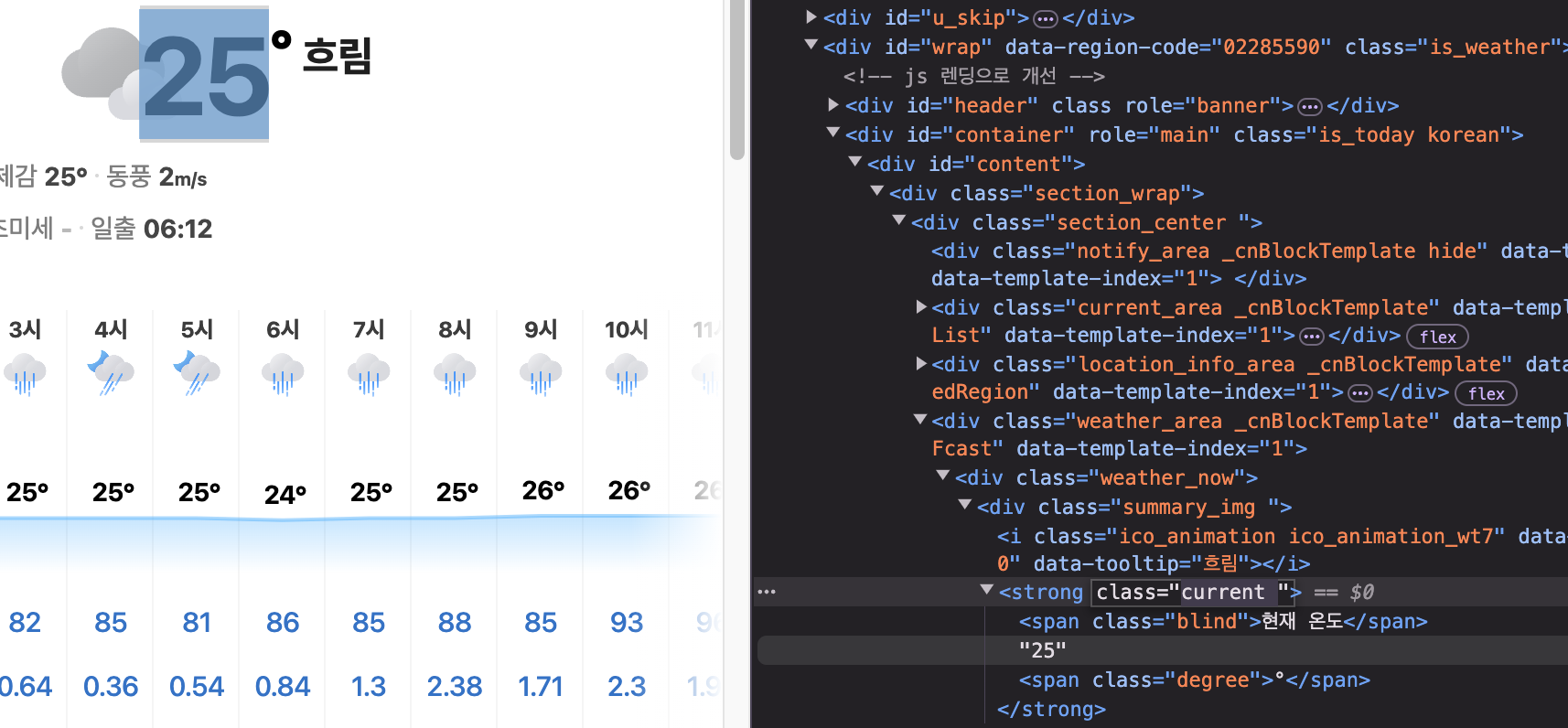
개발자 도구에서 해당되는 class 명인 'current'를 찾았다.
from selenium.webdriver.commom.by import By
current_location = browser.find_element(By.CLASS_NAME, 'current').text
print(current_location)
이런식으로 크롤링을 통해 내가 원하는 정보를 가져올 수 있었다.
참고로 사진과 실제 온도의 차이가 있지만, 시간이 지남에 따라 생긴 변화인점을 감안하시길 바란다.
데이터 전처리 Library (Numpy, Pandas)
1. Numpy
n차원의 배열을 파이썬에서 손쉽게 다룰 수 있게 도와주는 라이브러리다.

위와 같이 numpy를 불러왔다.
type() 함수
- 해당 데이터의 타입을 확인해보면 리스트가 numpy의 ndarray로 변환 된 것을 확인할 수 있다.
.ndim
- 해당 데이터의 차원을 확인하는 함수
.shape
- 해당 데이터의 행렬 형태를 보여주는 함수
.dtype
- 해당 데이터 값의 데이터 타입을 보여주는 함수
2. Pandas
데이터 분석의 핵심 라이브러리인 Pandas이며, 테이블 형태의 데이터를 다루는 DataFrame 자료형을 제공한다.
Numpy 기반에서 개발되었으며, 대용량의 데이터를 다룰 때 엑셀보다 속도가 훨씬 빠르다.
pandas 필수 함수
1. 파일 읽기, 쓰기 함수
- .read_csv('/경로'), read_excel(), read_html
- .to_csv('/경로'), to_excel()
2. 데이터 확인 함수
- .shape, .info, .columns, .dtypes, .head, .tail
3. 정렬
- .sort_values
4. column / row 삭제
- .drop(['column_name'], axis=1)
- .drop['row']
5. 특정 column 이름 변경
- .rename(columns={'A' : 'B'})
6. DataFrame 2개 합치기
- .concat([df1, df2])
pandas의 데이터 구조
1. Series
- 1개의 컬럼 값으로 구성된 1차원 Dataset
2. DataFrame
- rows & columns로 구성된 2차원 Dataset
3. Index
- 1 & 2의 unique ID
데이터 시각화 Library
1. Matplotlib
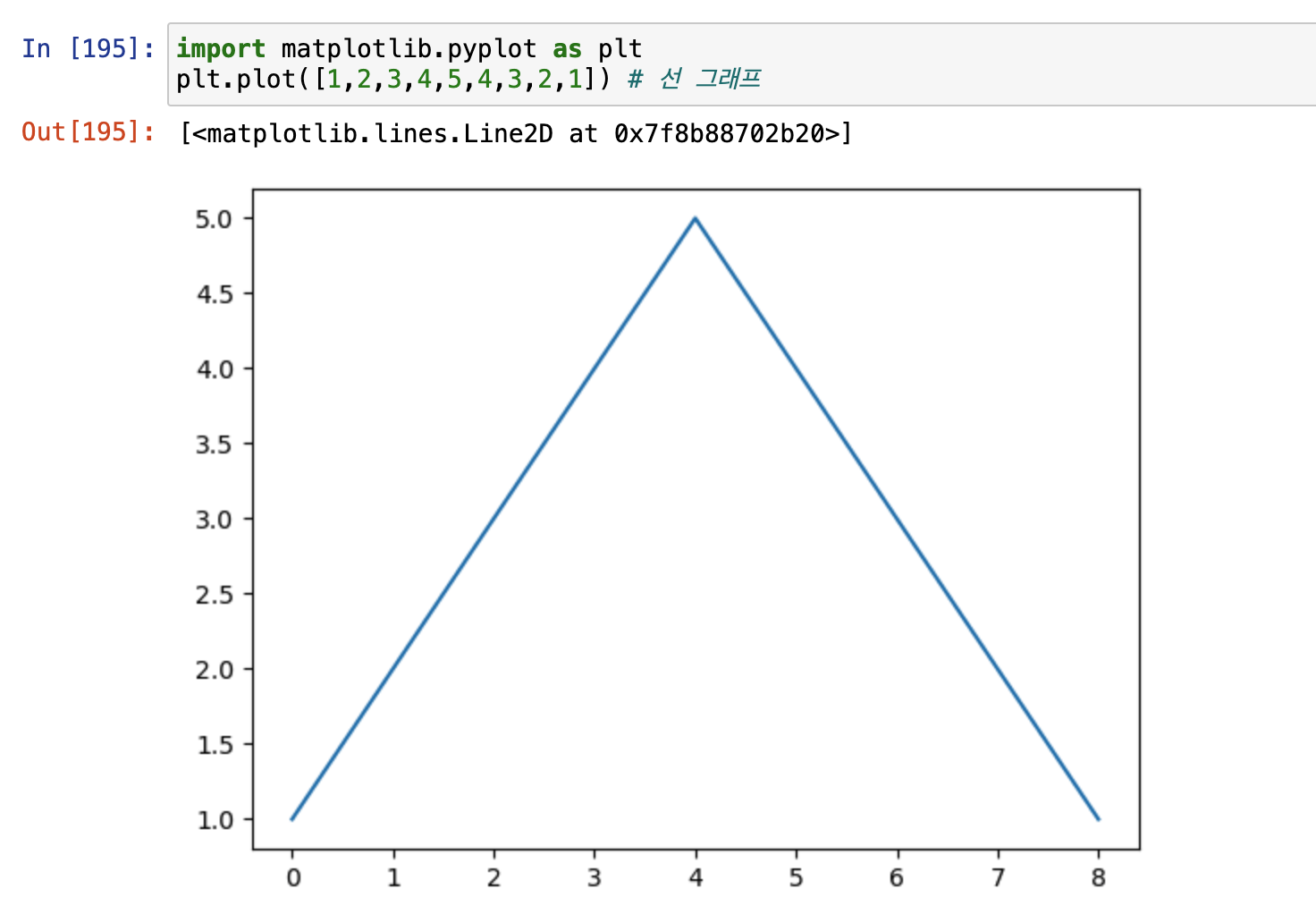
시각화 라이브러리를 사용하면 이와같이 데이터를 그려볼 수 있다.
2. SeaBorn
또 다른 시각화 라이브러리중 하나이고, data의 양은 많지 않지만 예쁘게 보고 싶을 때 사용한다.

먼저, seaborn이 없다면 설치를 진행한다.

import seaborn as sns
# tips 데이터 가져오기
tips = sns.load_dataset('tips')
tips먼저, 어떤 기준으로 시각화를 진행할지 살펴보기 위해 데이터를 불러왔다.

sns.get_dataset_names()참고로 seaborn에는 자체 내장 데이터셋이 존재하는데, 이 자료를 가지고 조작해보면서 연습을 해볼 수 있을 것이다.
기본적인 사용법은 여기까지이고, 이번에는 다른 데이터셋으로 시각화를 진행해보고자 한다.
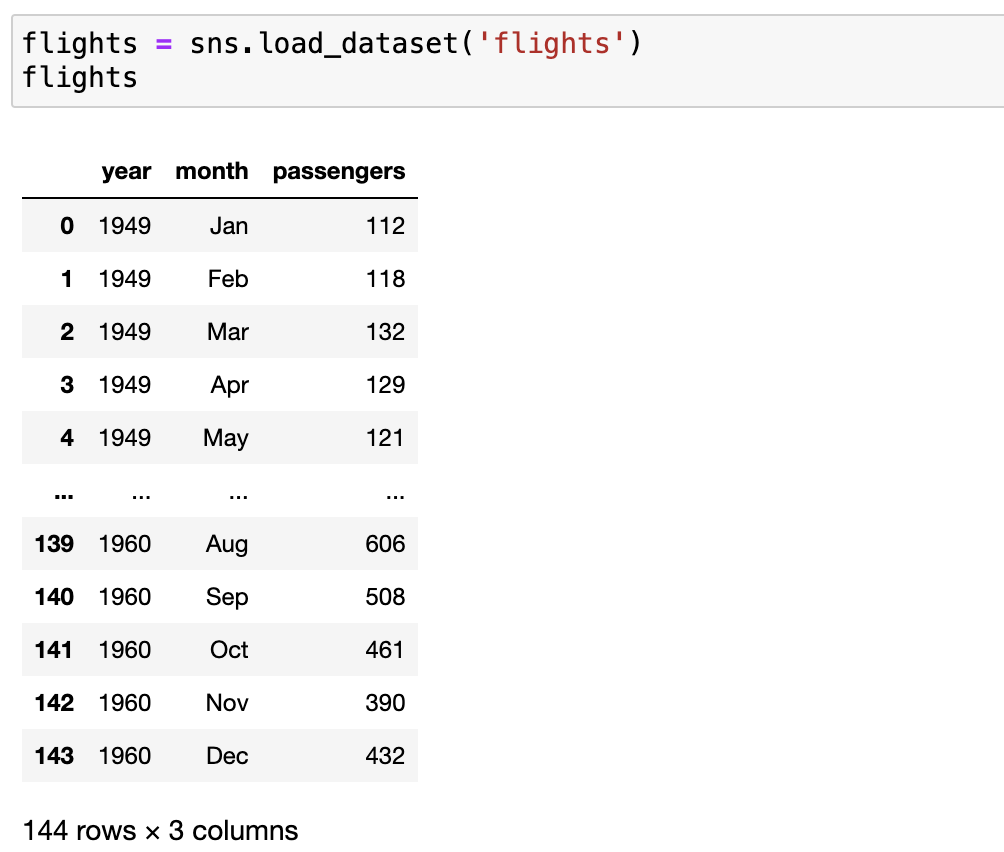
flights = sns.load_dataset('flights')
flights출력해보면 연도별 월별로 통계가 나와 있는것을 확인할 수 있다.
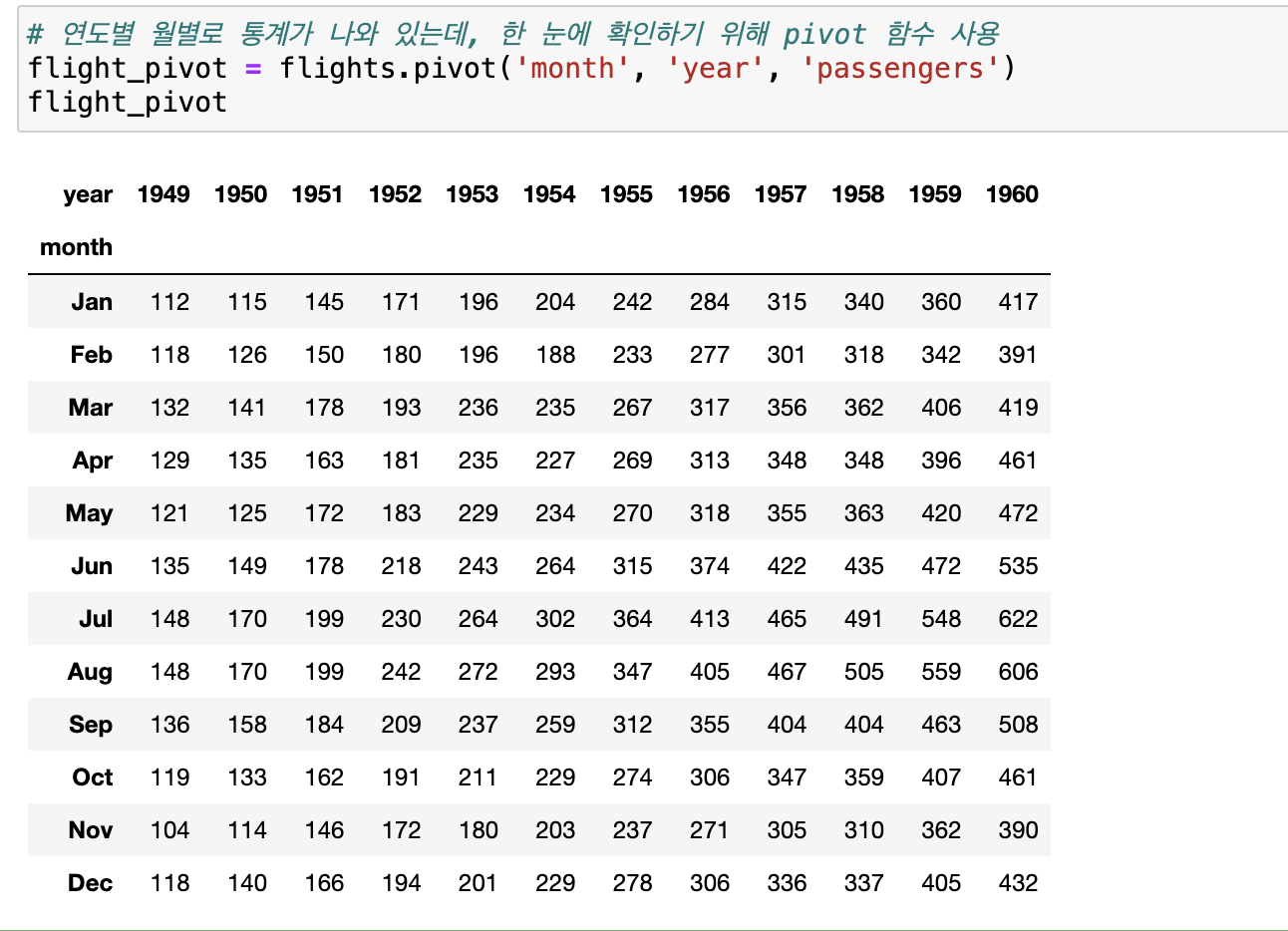
flight_pivot = flights.pivot('month', 'year', 'passengers')
flight_pivot
이 것을 한 눈에 확인하기 위해 pivot 함수 사용하였다.

sns.heatmap(flight_pivot, annot=True, fmt='d')위의 내용을 시각화하기 위하여, heatmap 이라는 함수를 사용하였다.
'데이터 분석(Data Analysis) > - 데이터 분석 부트캠프' 카테고리의 다른 글
| [패스트캠퍼스] 데이터 분석 부트캠프 12주차 학습일지 (1) | 2024.11.08 |
|---|---|
| [패스트캠퍼스] 데이터 분석 부트캠프 5주차 학습일지 (5) | 2024.09.20 |
| [패스트캠퍼스] 데이터 분석 부트캠프 3주차 학습일지 (3) | 2024.09.06 |
| [패스트캠퍼스] 데이터 분석 부트캠프 2주차 학습일지 (0) | 2024.08.30 |
| [패스트캠퍼스] 데이터 분석 부트캠프 1주차 학습일지 (0) | 2024.08.23 |

